AI / ML Tribune
Tracing Legal Patterns in the Courts: Predictive Modeling of California Appellate Case Outcomes from the Caselaw Access Project
Predicting California appellate outcomes — affirmed, reversed, vacated, remanded — from opinion text and case metadata, across five models from a majority-class baseline to a fine-tuned LegalBERT.
By Ambro Quach, Uma Krishnan, Serina Li & Chase Martin
Test accuracy by model — California appellate outcomes
Abstract
This project investigates whether we can predict the outcomes of California appellate court cases by using structured metadata and unstructured legal text. Leveraging the Harvard Caselaw Access Project, we filtered for California Appellate 4th and 5th District decisions between 1991 and 2017. Our objective was to classify each case as "affirmed," "reversed," "vacated," or "remanded" based on features including court division, citation count, case type, and the content of majority opinions. We trained a series of models beginning with a majority-class baseline, followed by logistic regression (with and without TF-IDF), random forest, and a fine-tuned LegalBERT neural network. To prevent data leakage from outcome-indicative phrases in the opinion text, we applied targeted sanitization using regular expressions. Categorical and numeric metadata features were encoded and scaled accordingly. Our best-performing model, LegalBERT, achieved a test accuracy of 73%, outperforming all three models: TF-IDF logistic regression (68%), TF-IDF random forest (68%), and logistic regression (53%). This study underscores the predictive value of legal text, the importance of careful preprocessing, and the feasibility of applying machine learning to support legal research and judicial transparency.
I. Introduction
Appellate decisions shape legal precedent, yet predicting their outcomes remains a challenging task. With millions of digitized rulings now available, there is growing potential to support legal research, promote public transparency, and ensure equitable access to justice, especially for pro se litigants. Our project explores whether the outcomes of California appellate court cases can be predicted using structured metadata and unstructured legal opinion text. We aim to uncover systemic patterns and potential biases in judicial decision-making and to contribute to the development of interpretable legal AI tools. In particular, we investigate the predictive value of metadata attributes in modern rulings (post-1991) and assess whether the semantic content of appellate opinions further improves outcome prediction.
Our models use appellate court decisions from 1991 to 2017, sourced from the Caselaw Access Project. The input to our models includes both structured metadata and unstructured text from the majority opinions. We implemented multiple modeling approaches—logistic regression (with and without TF-IDF vectorization), random forest, and a LegalBERT neural network architecture—to predict one of four possible outcomes: affirmed, reversed, vacated, or remanded.
II. Literature Review
Legal outcome prediction has grown into a well-established subfield of legal AI, with early models using TF-IDF and classifiers like SVMs or logistic regression to extract patterns from court opinions (Nikolaev & Savelyev, 2020). As legal datasets expanded, researchers began incorporating structured metadata, such as judge, region, and court division, revealing these features often rivaled textual inputs in predictive power.
Recent work has shifted toward transformer-based models, especially BERT variants pre-trained on legal corpora. LegalBERT (Chalkidis et al., 2020) and CaseHOLD (Zheng et al., 2021) demonstrated improved ability to model legal reasoning over bag-of-words approaches. These models show strong results but also raise concerns: as Zeleznikow (2023) and Ariai & Demartini (2024) caution, many legal prediction tasks risk data leakage when models learn from outcome-revealing language embedded in case opinions.
Our work builds on these insights. Like recent hybrid approaches, we combine structured metadata and unstructured text, but we extend prior work by applying a targeted sanitization process to mitigate leakage. By sanitizing outcome keywords, we can accurately assess how well models generalize from substantive case characteristics rather than memorizing label cues.
III. Data
Our cases are from California's Court of Appeal (Cal. App. 4th and 5th), drawn from the Harvard Caselaw Access Project (1991–2017). From 21,699 cases, we extracted 20,973 labeled records after filtering out cases with unknown outcomes. We generated outcome labels using keyword-based rules applied to the majority opinion text: Affirmed: 9,721; Reversed: 9,892; Vacated: 1,377; Remanded: 354. We scrubbed outcome keywords from the case body text to prevent data leakage on text-trained models. We frame this as a multiclass (affirmed, reversed, vacated, or remanded) classification task. The dataset was shuffled and randomly split into training (70%), validation (15%), and test (15%) sets.
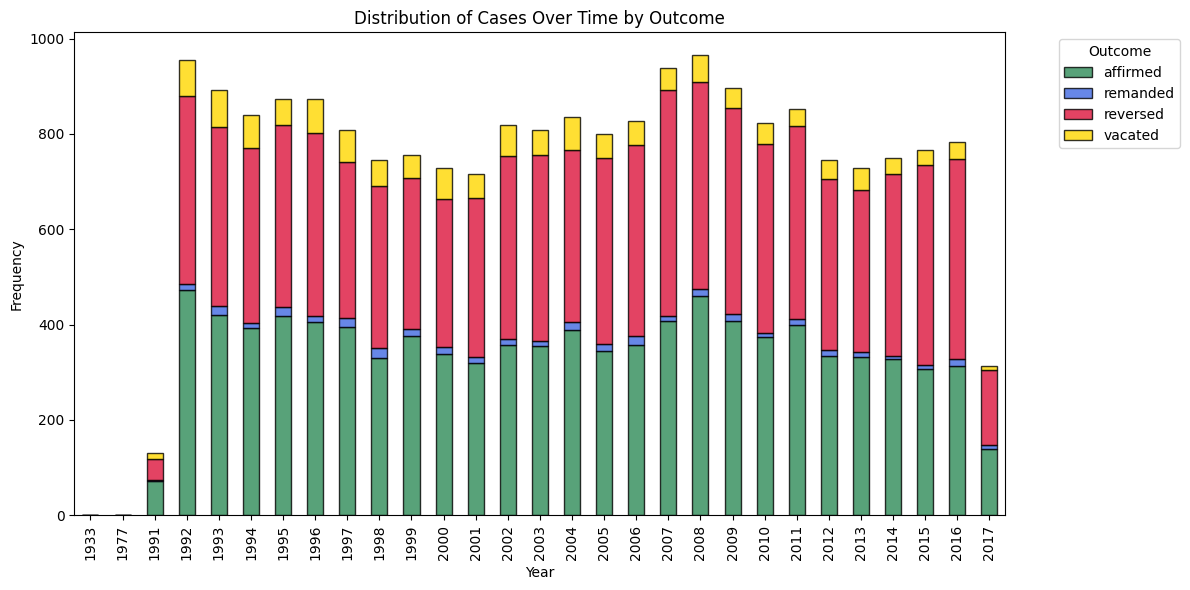
Fig 1. Trends Over Time: We visualized decisions by year from 1991 to 2017 to identify long-term patterns. Volume remained steady with a slight dip around 2008–2010, potentially due to archival gaps. Outcome rates (affirmed vs. reversed) showed no major shifts, suggesting stable appellate behavior across decades.
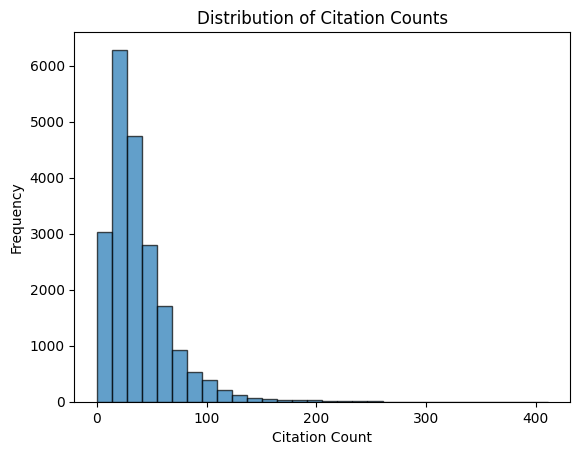
Fig 2. To measure doctrinal depth and case complexity, we analyzed how many cases each opinion cited using the cites_to field. Most opinions cited fewer than five cases, though some—such as People v. Sullivan—exceeded 350. While citation count was not highly correlated with outcome, it may serve as a weak proxy for legal salience or opinion richness.
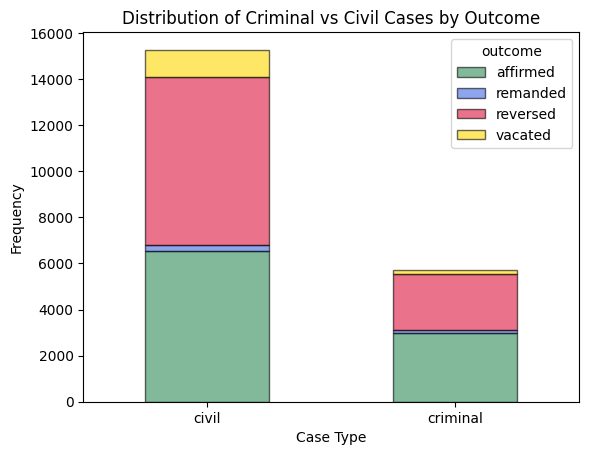
Fig 3. We classified a case as criminal if the title included "People v." — a standard format for state prosecutions in California. While this heuristic excludes edge cases (e.g., habeas petitions), it provides a reasonable domain split. Criminal cases were more likely to be affirmed, while civil cases showed higher reversal rates. This supports the inclusion of case type as a predictive feature.
For our input features, we normalized nested JSON structures to analyze key fields such as opinion_text, cites_to, author, and head_matter, and selected features relevant for classification. We extracted: Decision year (numeric); Court district and division (e.g., First Dist., Div. Three, extracted from docket); Opinion word count (proxy for complexity); Number of citations (proxy for complexity); Case type proxy (civil or criminal, inferred from case name); Judge name (opinion author, when available); and, Opinion text (processed for TF-IDF or transformer-based embeddings). Numeric features were standardized, and categorical features, such as court district, were one-hot encoded. Opinion text preprocessing used regex for label sanitization, followed by TF-IDF vectorization or tokenization depending on the model (e.g., tokenization for LegalBERT). Occurrences of outcome labels and common judgment patterns were removed from the case body text using regex pattern matching to reduce data leakage and ensure models learned from case substance rather than outcome language.
IV. Methods
We designed a supervised learning pipeline, integrating multiple models, to predict appellate outcomes in California court cases using both structured metadata and unstructured opinion text. Our workflow consisted of data preprocessing, feature engineering, model training, and evaluation using a stratified 70/15/15 train-validation-test split.
We implement five progressive models for multiclass legal case outcome prediction, each building upon the limitations of the previous method to achieve improved performance on complex legal document classification:
Baseline Model
As a benchmark, we implemented a simple majority-class classifier that always predicted the most frequent outcome in the training set. This model required no training and served to contextualize the effectiveness of subsequent models. It was used primarily to establish a lower bound for performance on the multiclass classification task.
Logistic Regression
This model utilized only structured metadata features, including the year of decision, court division, citation count, word count of the opinion, and case type (civil or criminal). Categorical features were one-hot encoded, and continuous features were standardized. We used a multinomial logistic regression model with class_weight='balanced' to address class imbalance. The regularization parameter C was selected using grid search.
TF-IDF + Logistic Regression
Combining TF-IDF vectorization with logistic regression is a strong next step baseline for a text classification task like this. The TF-IDF (Term Frequency-Inverse Document Frequency) transformation converts the casebody text into a numerical representation that highlights terms that are relatively unique or important within a document, relative to the collection of all documents. This reduces the influence of common, uninformative words when terms are assigned values. Adding TF-IDF text features allows logistic regression to try to learn linear decision boundaries in a high-dimensional feature space. We implemented the multiclass logistic regression model in Tensorflow and evaluated it with our pre-processed opinion text. This model helps us establish how much signal for the outcome exists in surface-level word patterns alone.
TF-IDF + Random Forest + Structured Metadata
This multiclass random forest classifier combined structured metadata and opinion text transformed by TF-IDF vectorization. Numerical values were passed through, but we needed to one-hot encode categorical features. Then, using a column transformer, we combined these transformations to a random forest classifier and realized that our results were imbalanced here as well, and consequently had to tune hyperparameters using a 3-fold grid search and adjust class weight. Random forest models also provide interpretable feature importance scores, and we assessed those as well.
Hybrid LegalBERT Neural Network
This hybrid architecture combines LegalBERT embeddings with metadata features through a custom neural network, enabling multi-modal learning that leverages both textual content and case characteristics.
Legal case outcomes depend not only on the textual content of opinions but also on contextual factors such as court hierarchy, case timing, citation patterns, and procedural aspects. A hybrid approach is essential because purely text-based models miss critical metadata signals, for example, appellate court cases have different reversal patterns than trial courts, and citation counts may indicate case significance. The neural network architecture enables learning of complex, non-linear interactions between textual features and metadata, interactions that neither direct feature concatenation (TF-IDF + LogReg) nor binary feature partitioning (Random Forest) can capture, which is important for understanding the multifaceted nature of legal decision-making.
The model processes legal text through LegalBERT to extract contextualized embeddings (768 dimensions) from the [CLS] token, while simultaneously processing metadata features through a separate neural network component. The metadata network consists of fully connected layers (input → 64 → 32 dimensions) with ReLU activations and dropout regularization to prevent overfitting. Feature integration occurs through concatenation of the BERT embeddings and processed metadata (800 total dimensions), which feeds into a final classification network with multiple hidden layers (800 → 128 → 64 → 4), also using ReLU activations and dropout. During training, backpropagation updates both LegalBERT parameters and metadata processing weights, enabling joint learning of outcome prediction across both components. The model uses gradient clipping, AdamW optimization with linear warmup scheduling, and validation-based early stopping to prevent overfitting.
V. Experiments and Results
Baseline vs. Logistic Regression
To establish a performance benchmark, we first implemented a baseline majority-class classifier that always predicted the most frequent outcome, "reversed." This yielded an overall test accuracy of 46%, but produced zero precision, recall, or F1-score for the remaining classes. The confusion matrix confirmed that all predictions fell into a single outcome category, highlighting the limitations of this approach in a highly imbalanced setting.
Next, we trained two logistic regression models using structured metadata features. 1) Unweighted Logistic Regression: This model used one-hot encoded categorical features (court division, case type) and scaled numerical features (year, citation count, word count). It achieved a validation accuracy of 53%. The model showed improved performance on the "affirmed" and "reversed" classes but continued to struggle with the underrepresented "remanded" and "vacated" classes. 2) Balanced Logistic Regression with Grid Search: To improve performance on minority classes, we retrained the model using class_weight='balanced' and performed grid search over the regularization parameter C. The best-performing configuration (C=0.01) maintained the 53% validation accuracy, but increased the weighted F1-score to 0.51, indicating better handling of class imbalance. Both models demonstrated that structured metadata alone offers a moderate predictive signal, but is insufficient for capturing the full complexity of appellate decisions, particularly when labels are imbalanced and nuanced.
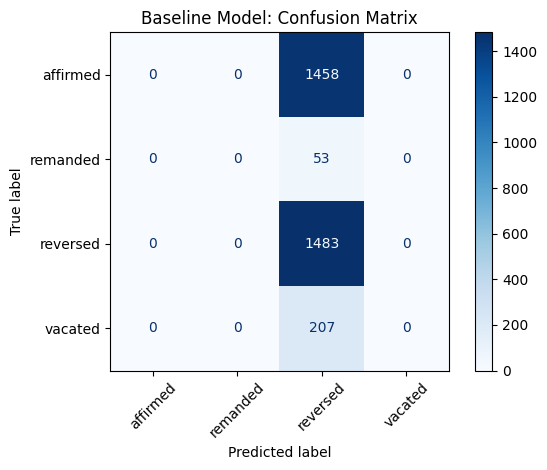
Fig 4A. Baseline model confusion matrix — every prediction collapses into the single majority class (“reversed”).
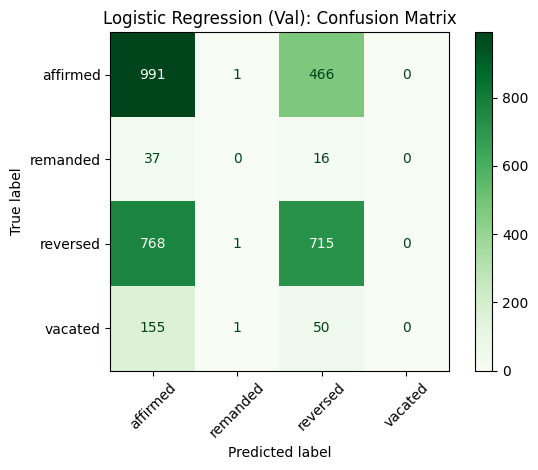
Fig 4B. Logistic-regression (validation) confusion matrix, metadata-only features.
TF-IDF Logistic Regression
Our multiclass TF-IDF logistic regression model was implemented as a single-dense-layer softmax classifier using Tensorflow, with an Adam optimizer and sparse categorical entropy loss. We used a grid search approach to settle on a TF-IDF vocabulary size of 5,000 tokens, with both unigrams and bigrams included. To tune the learning rate and batch size, we used Keras Tuner's Hyperband search over a logarithmic scale for the learning rate (0.0001 to 0.1) and batch sizes of 16, 32, or 64. Early stopping was applied using callback with a patience of three epochs on the validation loss. The best model from the tuner achieved 80.5% training accuracy and 67.1% test accuracy, showing moderate overfitting on the training data without great generalization capabilities. Its macro-average F1 score was 0.51, with strong performance on the "affirmed" and "reversed" classes (F1 scores of 0.70 and 0.66, respectively). The model showed lower precision and recall for the minority "remanded" and "vacated" classes. These results outperform the baseline, making it a strong early benchmark for the text-based outcome prediction.
TF-IDF Random Forest
We implemented a multiclass Random Forest classifier using both opinion text and structured metadata. We transformed opinion text with a TF-IDF vectorizer (max 5,000 features, unigrams and bigrams, min_df=5), passed through numeric (year, word_count, citation_count) features as is, and processed categorical (court_division, case_type) features via one-hot encoding. We used a 3-fold GridSearchCV tuned with hyperparameters n_estimators ∈ {100, 200}, max_depth ∈ {20, 30}, max_features ∈ {sqrt, log2}, and min_samples_split ∈ {2, 5, 10}, with class_weight = 'balanced'. We tuned hyperparameters to address class imbalance, as vacated and remanded cases were underrepresented.
Our model achieved 68% accuracy and a weighted F1-score of 0.68 on validation, with similar test results (68%, 0.67). F1 scores were highest for affirmed (0.70) and reversed (0.68), moderate for vacated (0.60–0.65), and lowest for remanded (~0.22–0.24), likely due to class imbalance. Confusion matrices showed substantial affirmed ↔ reversed misclassification (over 400 cases each way) and frequent misclassification of remanded as reversed.
Feature importance analysis indicated the top predictors were TF-IDF terms linked to legal writs and mandates. This suggests predictive power was driven primarily by procedural language, highlighting opportunities to improve minority class performance via oversampling, domain-specific features, or imbalance-aware algorithms.
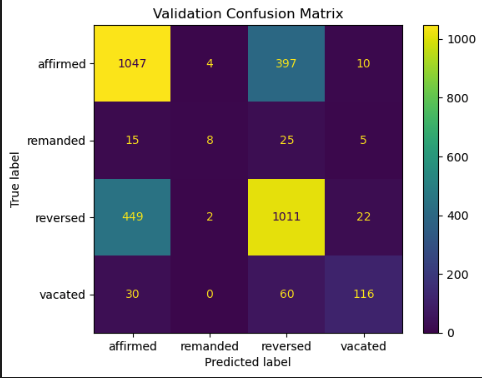
Fig 5A. Random-forest validation confusion matrix (TF-IDF + structured metadata).
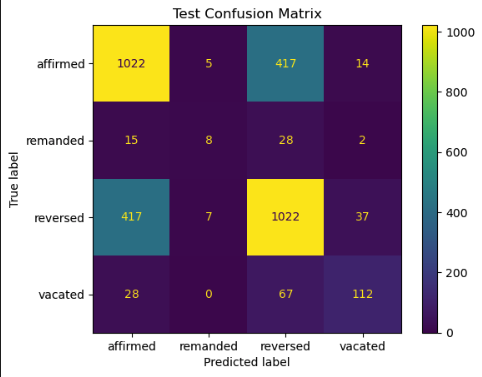
Fig 5B. Random-forest test confusion matrix.
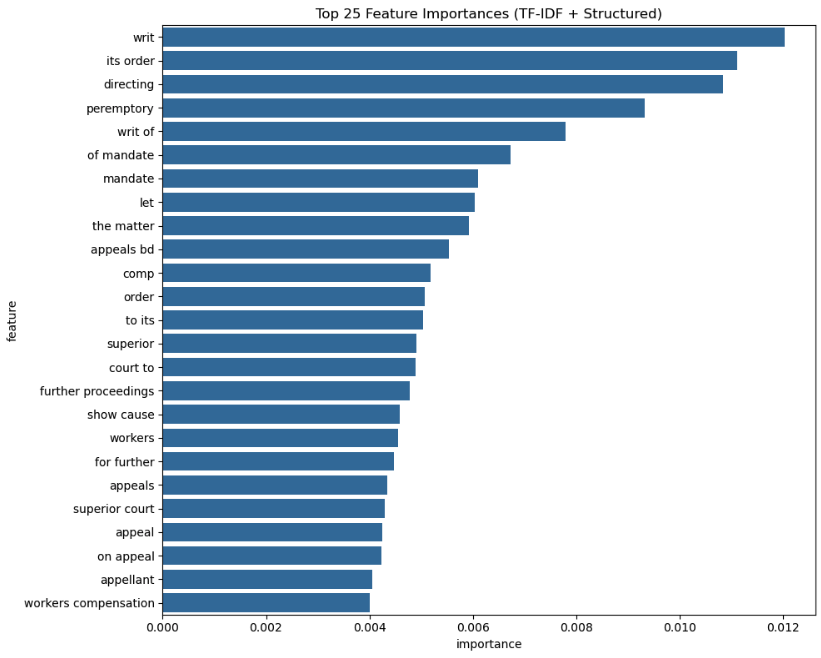
Fig 6. Top-25 feature importances (TF-IDF + structured) — procedural terms like writs and mandates dominate.
Hybrid LegalBERT Neural Network
Our hybrid LegalBERT neural network model, which combines text analysis with structured metadata, shows a clear learning trajectory to predict legal outcomes. In the training phase, the model's performance improved significantly, with training loss consistently decreasing and accuracy rising from 46% to nearly 90%.
However, the loss and accuracy curves showed signs of overfitting after the third epoch. The training loss continued to fall. Yet, the validation loss began to increase, and validation accuracy plateaued at 71-72%. To mitigate this, we implemented early stopping to prevent the model from memorizing the training data and ensured better generalization to new cases. On our final test set, the model achieved an overall accuracy of 73.08%. While this is a reasonable result, there is a significant imbalance in predictive performance when we look at class-specific metrics.
The model performed best on the most frequent outcomes:
- Affirmed: The model had a strong recall of 82%, meaning it successfully identified most of the cases that were actually affirmed. However, its precision was lower at 71%, indicating that its "affirmed" predictions were not always reliable.
- Reversed: The model's performance was most balanced for this class, achieving an F1-score of 72%. Its precision for "reversed" was quite dependable at 77%, although it failed to identify a significant portion of true reversed cases with 67% recall.
The model struggled with less frequent outcomes:
- Remanded: The model performed poorly on this class, with a low recall of just 28%. This suggests a significant difficulty in correctly identifying cases that should be remanded, likely due to the limited number of "remanded" samples in our dataset.
- The large disparity between the macro-averaged metrics (which average performance across all classes equally) and the weighted-averaged metrics (which account for class frequency) confirms that the model's overall performance is driven by its success on common outcomes.
In conclusion, our model shows strong promise for predicting frequent legal outcomes but requires further refinement to effectively handle less-represented classes like "remanded" and "vacated."
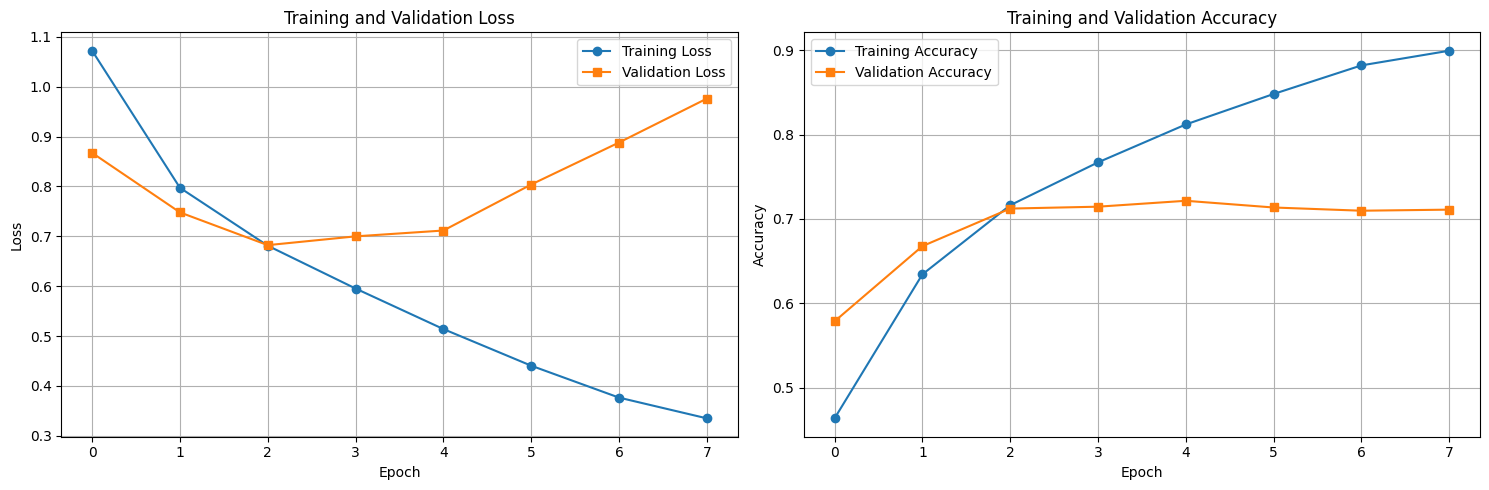
Fig 7. Training and validation loss / accuracy for the hybrid LegalBERT model — validation accuracy plateaus while training loss keeps falling (overfitting after epoch 3).
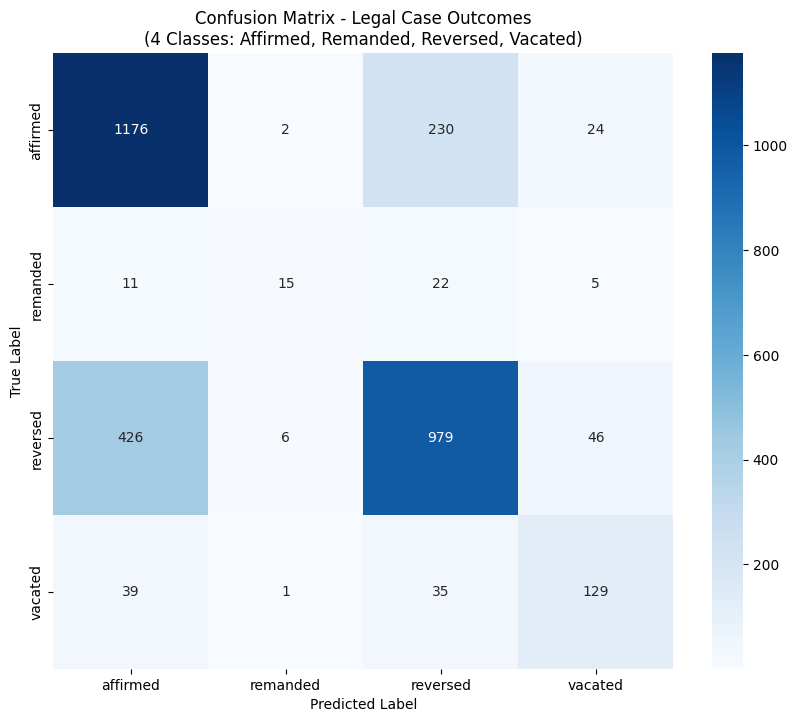
Fig 8. Hybrid LegalBERT confusion matrix on the test set (four classes).
VI. Discussion and Challenges
Our results demonstrate that even simple structured metadata—such as court division, year, and citation count—can offer moderate predictive power in modeling appellate case outcomes. However, adding unstructured opinion text substantially improved performance, especially when using transformer-based models like LegalBERT. This supports prior findings that legal text holds rich semantic signals that help differentiate between case outcomes.
That said, this project revealed important limitations. First, unstructured legal opinion text presents challenges in both outcome extraction and modeling. Inconsistent formatting and embedded keywords introduced risks of data leakage. We mitigated this by applying targeted text sanitization, which significantly lowered performance metrics, confirming prior inflation due to leakage. Second, training advanced models like LegalBERT required careful hyperparameter tuning and long runtimes, which limited experimentation. Freezing layers and using early stopping helped reduce overfitting, but did not fully resolve class imbalance issues—remanded and vacated cases remained difficult to predict due to low representation. Finally, as non-lawyers, we had to rely on external resources to interpret court metadata and opinion structures. While this informed our feature selection, future work could benefit from domain experts to refine label extraction and model evaluation.
Overall, the project highlights the promise and pitfalls of using machine learning in the legal domain. Predictive models can uncover patterns in judicial decision-making, but they require careful design to avoid misleading results.
VII. Conclusion
Our project demonstrates the feasibility and challenges of predicting appellate case outcomes using machine learning. Among the models tested, our best-performing approach was a fine-tuned LegalBERT classifier, which achieved 73% test accuracy after outcome keyword sanitization, outperforming the metadata-only logistic regression baseline by 20 percentage points. These results suggest that while structured metadata holds moderate predictive value, opinion text provides richer signals when appropriately preprocessed.
Future work could improve label granularity to better capture complex rulings such as partial reversals or combined outcomes. Expanding the dataset beyond California could increase minority class representation, while incorporating judge- or court-level embeddings may uncover institutional patterns. Citation network features and PageRank-style metrics also offer promising paths for assessing legal influence. Beyond outcome prediction, we see opportunities to extend this modeling framework to support docket management and assist legal scholars in identifying precedent-setting cases based on content and context.
References
- Ariai, F., & Demartini, G. (2024). Natural language processing for the legal domain: A survey of tasks, datasets, models, and challenges. arXiv preprint arXiv:2410.21306. https://arxiv.org/pdf/2410.21306
- Lai, J., et al. (2023). Large language models in law: A survey. arXiv preprint arXiv:2312.03718. https://arxiv.org/pdf/2312.03718
- Zheng, L., Choi, B., & Lee, J. (2021). When does pretraining help? Assessing self-supervised learning for law and the CaseHOLD dataset. arXiv preprint arXiv:2104.08671. https://arxiv.org/abs/2104.08671
- Falduti, M. (2021). Law and data science: Knowledge modeling and extraction from court decisions. Università degli Studi di Milano.
- Huang, Z., Low, C., Teng, M., Zhang, H., Ho, D. E., Krass, M. S., & Grabmair, M. (2021). Context-aware legal citation recommendation using deep learning. arXiv preprint arXiv:2106.10776. https://arxiv.org/abs/2106.10776
- Ansari, T., Dhillon, H. S., & Singh, M. (2024). Machine learning model to predict results of law cases. In 2024 Fourth International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT). IEEE.
- Surden, H. (2021). Machine learning and law: An overview. In R. Vogl (Ed.), Research handbook on big data law (pp. 255–270). Edward Elgar Publishing.
- Zeleznikow, J. (2023). The benefits and dangers of using machine learning to support making legal predictions. WIREs Data Mining and Knowledge Discovery, 13(5), e1505.
A machine-learning project from UC Berkeley's School of Information, by Ambro Quach, Uma Krishnan, Serina Li, and Chase Martin.